在 GCP 環境下使用 Ansible 自動化建立 ELK Stack

📔心得
最近,我在探索 Ansible 自動化工具的過程中,決定運用它來建立 ELK Stack,這是我之前使用 Docker 建立的經驗的延伸。在這個過程中,我想分享一下我的學習心得。
- 尋找資源
我開始了解 ELK Stack 的安裝過程,首先閱讀了官方文件,熟悉了整個設置流程。接著,我尋找 Ansible 中相關的模組,這讓我更好地理解如何在 Ansible 中實現相同的步驟。
- 目錄結構的重要性
在撰寫 Ansible Playbook 過程中,我學到了良好的目錄結構是多麼重要。我從最初只有一個主要的 main.yml 開始,逐漸分解出根目錄下的多個 .yml 檔案,然後使用 include 來引入任務。這種結構讓整個 Playbook 更加模組化,易於管理。
- 使用模板和變數
在創建模板時,我發現了 Jinja2 語法的威力。我可以直接套用變數,這讓我的模板在複製到目標主機時能自動載入所需的參數。此外,我還學會了如何根據我的主機清單(inventory)來動態設定這些參數,這真是強大的功能。
- 感謝凍仁大的指南
我要特別感謝凍仁大(作者)的 Ansible 教程,我從他的 Ansible GitBook 中學到了許多寶貴的資訊。他的教程簡潔明瞭,對於初學者也非常友好。他的教程甚至提供了 Ansible 在使用 Docker Compose 方面的實際練習,這讓我能更好地掌握 Ansible 的操作技巧。另外,使用 Jupyter Notebook 執行 Ansible 模組也讓我的學習過程更加便利。
如果你對於 Ansible 自動化配置技巧感興趣,我推薦你閱讀這份凍仁大的 Ansible 指南,連結在下方:
🔗凍仁大ansible指南 –> 現代 IT 人一定要知道的 Ansible 自動化組態技巧
此外,我還將我使用 Ansible 建立 ELK Stack 的 Playbook 放在了以下的 GitHub 倉庫,歡迎參考:
🔗Ansible-ELK repo –> Ansible-ELK
這次的學習讓我更深入地理解了自動化的價值,也讓我更有信心在日後的專案中運用 Ansible 來簡化配置流程。
👨💻簡介
在 GCP 環境下使用 Ansible Playbook 建立 ELK Stack
- Elasticsearch:主要會先需要先跑init master,接著再去跑seed host去加入master組成cluster架構,邏輯上還有可修改的地方,目前先以兩份yaml分開跑下去做建立,在跑完init master後會先建立iim以及index template
- Logstash:直接將pipeline等設定直接複製到主機中。
- Kibana:設定與 Elasticsearch 的連接資訊。
📁資料夾結構
.
├── create_elasticsearch_master_instance.yaml
├── create_elasticsearch_slave_instance.yaml
├── create_filebeat_instance.yaml
├── create_kibana_instance.yaml
├── create_logstash_instance.yaml
├── files
│ ├── elasticsearch
│ │ ├── api.sh
│ │ ├── certs
│ │ └── elasticsearch.repo
│ ├── kibana
│ │ └── kibana.repo
│ └── logstash
│ ├── conf.d
│ │ └── logstash.conf
│ ├── logstash.repo
│ ├── logstash.yml
│ └── pipelines.yml
├── group_vars
│ └── all
│ ├── env.yml copy.example
│ └── package.yml
├── inventory
│ └── elk.test.node
├── inventory.instance.create.yml.example
├── README.md
├── roles
│ ├── elasticsearch
│ │ ├── tasks
│ │ │ ├── create_disk.yml
│ │ │ ├── install_elastic.yml
│ │ │ ├── main.yml
│ │ │ ├── setup_disk.yml
│ │ │ ├── setup_elastic_master.yml
│ │ │ └── setup_elastic_slave.yml
│ │ └── templates
│ │ └── elasticsearch.yml.j2
│ ├── instance
│ │ └── tasks
│ │ ├── create.yml
│ │ └── setup.yml
│ ├── kibana
│ │ ├── tasks
│ │ │ └── main.yml
│ │ └── templates
│ │ └── kibana.yml.j2
│ └── logstash
│ └── tasks
│ └── main.yml
└── vars
├── elasticsearch
│ ├── elasticsearch_var.yml
│ └── elasticsearch_var.yml.example
├── instance
│ ├── instance_var.yml
│ └── instance_var.yml.example
├── kibana
│ ├── kibana_var.yml
│ └── kibana_var.yml.example
└── logstash
├── logstash_var.yml
└── logstash_var.yml.example
🔰基礎介紹
- 設定機器資訊:複製好inventory.instance.create.yml.example後,可參考inventory裡的設定,主要設定gcp的資訊,elasticsearch的node_role為data_role,可參考以下連結
Elasticsearch Multi-Tier Architecture | Hot, Warm, Cold & Frozen
設定group_vars的env.yml,改成自己的gcp的專案以及要設定的region
設定vars裡的相對yml,可參考範例
- elasticsearch:主要設定掛載的硬碟資訊
- kibana,logstash:設定elasticsearch的host資訊
🎯setup
elasticsearch_master -> elasticsearch_slave -> logstash -> kibana
- 指令
ANSIBLE_HOST_KEY_CHECKING=False ansible-playbook -i inventory.instance.create.yml create_xxx_instance.yaml -v
- golang
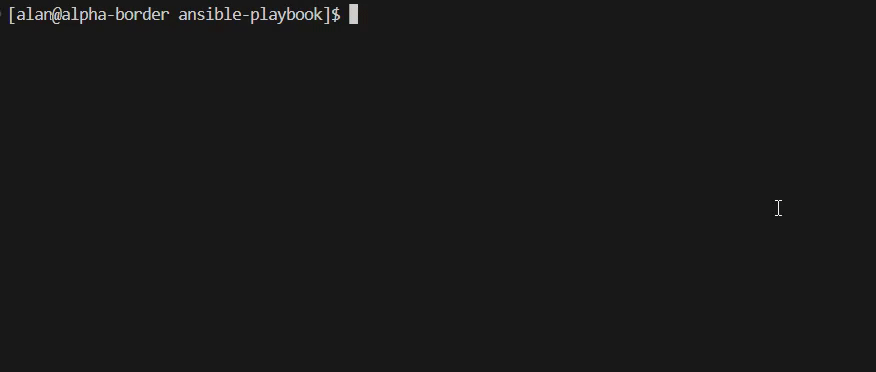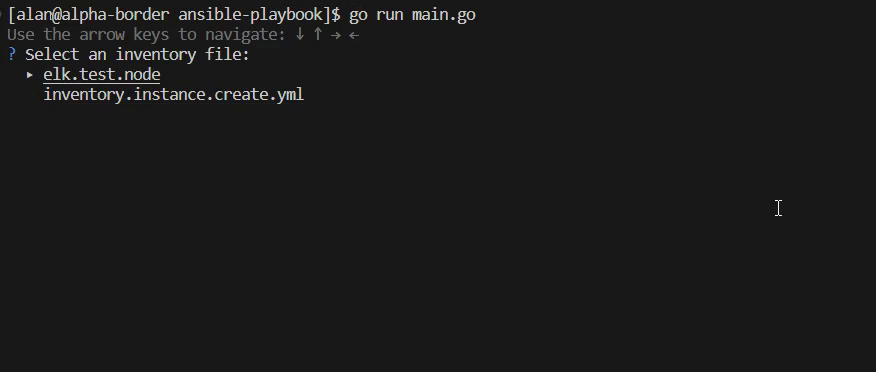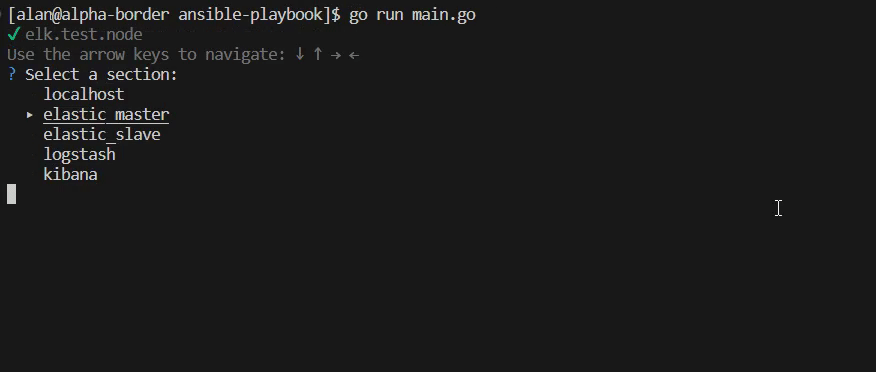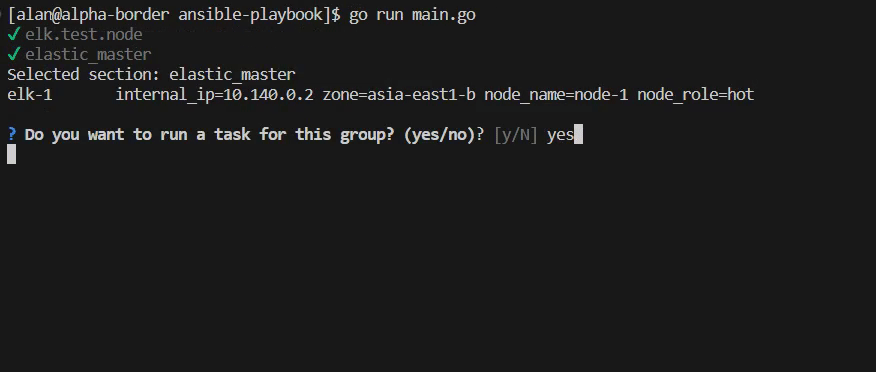
✅TODO
- elasticsearch playbook 優化
- 添加filebeat role
- disk 修改建置資料夾